Usando o Tf-idf com os clássicos da política
TF-IDF
Análise de Texto
Maquiavel
Hobbes
Marx
Introdução
Se você usar o código ou as informações deste guia em um trabalho publicado, solicito que cite-o como uma fonte nas referências bibliográficas.
DUTT-ROSS,Steven Usando o Tf-idf com os clássicos da política. Rio de Janeiro. 2020. mimeo. Disponível em: https://blog.metodosquantitativos.com/tf-idf/
Você não precisa usar o R… pode usar o Python também.
Aprender análise de texto no R me permitiu explorar novos tópicos. Nesta postagem, tentarei explicar o que é a frequência inversa de documentos com frequência de termo (tf-idf) e como ela pode nos ajudar a explorar palavras importantes em um corpus de documentos. A análise ajuda a encontrar palavras comuns em um determinado documento, mas são raras em todos os outros documentos.
Freqüência inversa de documentos (Inverse Document Frequency - IDF)
A frequência inversa do documento é responsável pela ocorrência de uma palavra em todos os documentos, atribuindo um valor mais alto às palavras que aparecem em menos documentos. Nesse caso, para cada termo, vamos calcular o log da razão de chances de todos os documentos dividido pelo número de documentos em que a palavra aparece. Em uma equação seria:
\[ idf = \log {\frac{\textrm{N documentos no corpus}}{\textrm{n documentos contendo o termo}}}\]
Nesse caso, se tivermos 9 documentos e nosso termo aparecer em todos os 9 documentos, teremos o seguinte valor idf: $ log_e() = 0 $. E se tivermos um termo que apareça em apenas 1 documento dos 9 documentos? Teremos o seguinte: $ log_e() = 2,197 $.
Então, omo nosso numerado sempre permanece o mesmo (N documentos no corpus), o idf de uma palavra depende do grau em que essa palavra é comum entre os documentos. Palavras que aparecem em um pequeno número de documentos terão um IDF mais alto, enquanto palavras comuns em todos documentos terão um IDF mais baixo.
Frequência inversa de documentos com a frequência de termo (*Term-Frequency Inverse Document Frequency - TFIDF)
Depois de obter a frequência do termo e a frequência inversa de documentos para cada palavra, podemos calcular o tf-idf: \(tf(t,d) \cdot idf(t,D)\) onde \(D\) é o corpus de documentos.
Em resumo: Os dois parâmetros utilizados para calcular o tf-idf fornecem a cada palavra um valor por sua importância para esse documento naquele corpus de documentos.
Geralmente, usamos palavras comuns em um documento e raras em todos os documentos. Assim destacamos o que é importante, isto é, contribui para a compreensão de um documento em comparação com todos os outros documentos.
Figure 1: Com o tf-idf, podemos calcular o quanto é comum uma palavra em um documento e o quanto rara é entre documentos.
O banco de dados
Vamos implementar o método em quatro grandes livros de Ciência Política: ’ A República’ (Platão), ‘O Príncipe’ (Maquiavel), ‘O Leviatã’ (Hobbes) e o livro ‘Contribuição para a Crítica da Economia Política’ do Kark Marx. Infelizmente, não encontrei o Capital inteiro 😿 😠.
Por fim, vamos comparar o tf-idf com uma análise de contagem de palavras e como o uso de ambos pode beneficiar sua exploração de texto.
library(gutenbergr)
#nao encontrei o capital
Marx <- gutenberg_download(46423) # Contribuição para a Crítica da Economia Política
#Marx2 <- gutenberg_download(31193) # Manifesto of the Communist Party
Hobbes <- gutenberg_download(3207)
Maquiavel <- gutenberg_download(1232)
Platao <- gutenberg_download(150)
#Adam_Smith <- gutenberg_download(3300)
#Mill <- gutenberg_download(34901)Vários livros contêm seções no início ou no final que não são relevantes para nossa análise. Por exemplo, longas introduções de estudiosos contemporâneos. Isso pode confundir a nossa análise e, portanto, vamos excluí-las. Para conduzir nossa análise, também precisamos de todos os livros em um unico objeto.
Assim que limpar os livros, é assim que nosso texto se parece:
remover_texto_desnecessario <- function(book, low_id, top_id = max(rowid), author = deparse(substitute(book))){
book %>%
mutate(author = as.factor(author)) %>%
rowid_to_column() %>%
filter(rowid >= {{low_id}}, rowid <= {{top_id}}) %>%
select(author, text, -c(rowid, gutenberg_id))}
books <- rbind(
remover_texto_desnecessario(Marx, 157,6875),
remover_texto_desnecessario(Hobbes, 360, 22317),
remover_texto_desnecessario(Maquiavel, 464, 3790),
remover_texto_desnecessario(Platao, 606))## # A tibble: 47,959 x 2
## author text
## <fct> <chr>
## 1 Marx ""
## 2 Marx "I consider the system of bourgeois economy in the following order:"
## 3 Marx "_Capital_, _landed property_, _wage labor_; _state_, _foreign trade_~
## 4 Marx "_world market_. Under the first three heads I examine the conditions"
## 5 Marx "of the economic existence of the three great classes, which make up"
## 6 Marx "modern bourgeois society; the connection of the three remaining head~
## 7 Marx "is self evident. The first part of the first book, treating of capit~
## 8 Marx "consists of the following chapters: 1. Commodity; 2. Money, or simpl~
## 9 Marx "circulation; 3. Capital in general. The first two chapters form the"
## 10 Marx "contents of the present work. The entire material lies before me in ~
## # ... with 47,949 more rowsCada linha é um texto com capítulos separados por títulos e uma coluna referenciando quem é o autor. O banco de dados consiste em ~ 45.000 linhas com o texto de quatro livros. Tf-idf também pode ser feito em qualquer n-grama que escolhermos (número de palavras subsequentes). Poderíamos calcular o tf-idf para cada bigrama de palavras (duas palavras), trigrama, etc. Vamos começar o tf-idf com o unigrama. Como o texto está na forma de frases, então vamos dividi-lo em palavras únicas (tidy).
## # A tibble: 12 x 4
## # Groups: author [4]
## author word n sum_words
## <fct> <chr> <int> <int>
## 1 Hobbes the 14536 207849
## 2 Hobbes of 10523 207849
## 3 Hobbes and 7113 207849
## 4 Platao the 7054 118639
## 5 Marx the 5827 71379
## 6 Platao and 5746 118639
## 7 Marx of 5394 71379
## 8 Platao of 4640 118639
## 9 Marx in 2215 71379
## 10 Maquiavel the 2006 34821
## 11 Maquiavel to 1468 34821
## 12 Maquiavel and 1333 34821Vemos que as stopwords dominam a frequência das ocorrências. Isso faz sentido, pois é comumente usado, mas geralmente não são úteis para aprender sobre o texto. Devemos banir essas palavras do texto.
Começaremos explorando como as frequências das palavras ocorrem em um texto:
## Warning: Removed 558 rows containing non-finite values (stat_bin).## Warning: Removed 4 rows containing missing values (geom_bar).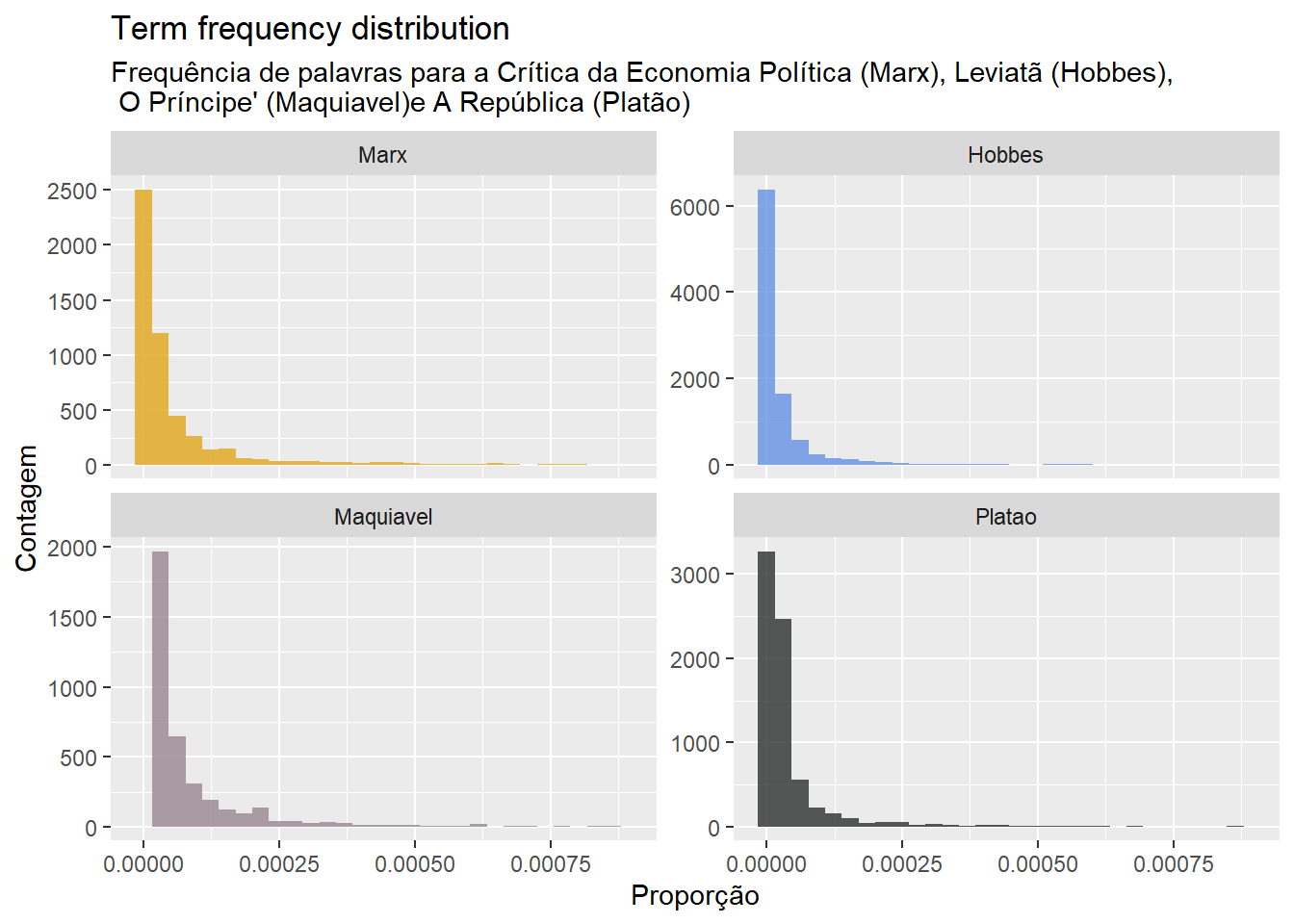
O gráfico acima mostra a frequência dos termos nos documentos. Vemos que algumas palavras que aparecem com frequência (proporção mais alta = lado direito do eixo x) e muitas palavras mais raras (proporção baixa).
Para ajudar a encontrar palavras úteis com o tf-idf mais alto de cada livro, removeremos as stopwords antes de encontrar as palavras com um valor alto de tf-idf:
## Joining, by = "word"| Author | Word | n | Sum words | Term Frequency | IDF | TF-IDF |
|---|---|---|---|---|---|---|
| Marx | money | 693 | 71379 | 0.0248851 | 0.0000000 | 0.0000000 |
| Hobbes | god | 1047 | 207849 | 0.0149024 | 0.0000000 | 0.0000000 |
| Maquiavel | prince | 185 | 34821 | 0.0172704 | 0.2876821 | 0.0049684 |
| Platao | true | 485 | 118639 | 0.0152953 | 0.0000000 | 0.0000000 |
| Amostra aleatória de palavras e seus valores de tf-idf correspondentes |
Acima, temos nosso tf-idf para uma determinada palavra de cada documento.
Para Hobbes, a palavra “Deus” aparece 1047 vezes, portanto, tem um \(Term Frequency\) de $ e um idf de 0 (como aparece em todos os documentos), portanto, ele terá um tf-idf de 0.
No caso do Maquiavel, a palavra príncipe aparece 185 vezes, com um \(Term Frequency\) of \(\frac{185}{34821}\), resultando em uma proporção de 0,0173. A palavra príncipe tem um idf de 0,288, como existem 4 documentos e ele aparece em 3 deles, um valor total de tf-idf = 0,0049684.
Gráfico de tf-idf
À medida que concluímos nossa análise tf-idf, não queremos ver todas as palavras e seus tf-idf, mas apenas palavras com o valor mais alto de tf-idf para cada autor, indicando a importância de uma palavra para um determinado documento. Podemos analisar essas palavras plotando as 10 palavras tf-idf mais valorizadas para cada autor:
ggplot(data = books_for_plot, aes(x = word, y = tf_idf, fill = author))+
geom_col(show.legend = FALSE)+
labs(x = NULL, y = "tf-idf")+
coord_flip()+
scale_x_reordered()+
facet_wrap(~ author, scales = "free_y", ncol = 2)+
labs(title = "<b>Term Frequency Inverse Document Frequency</b> - Ciência Política",
subtitle = "tf-idf para ’ A República’ (Platão), ‘O Príncipe’ (Maquiavel), ‘O Leviatã’ (Hobbes) \n e ‘Contribuição para a Crítica da Economia Política’ do Kark Marx")+
scale_fill_manual(values = plot_colors)+
theme(plot.title = element_markdown())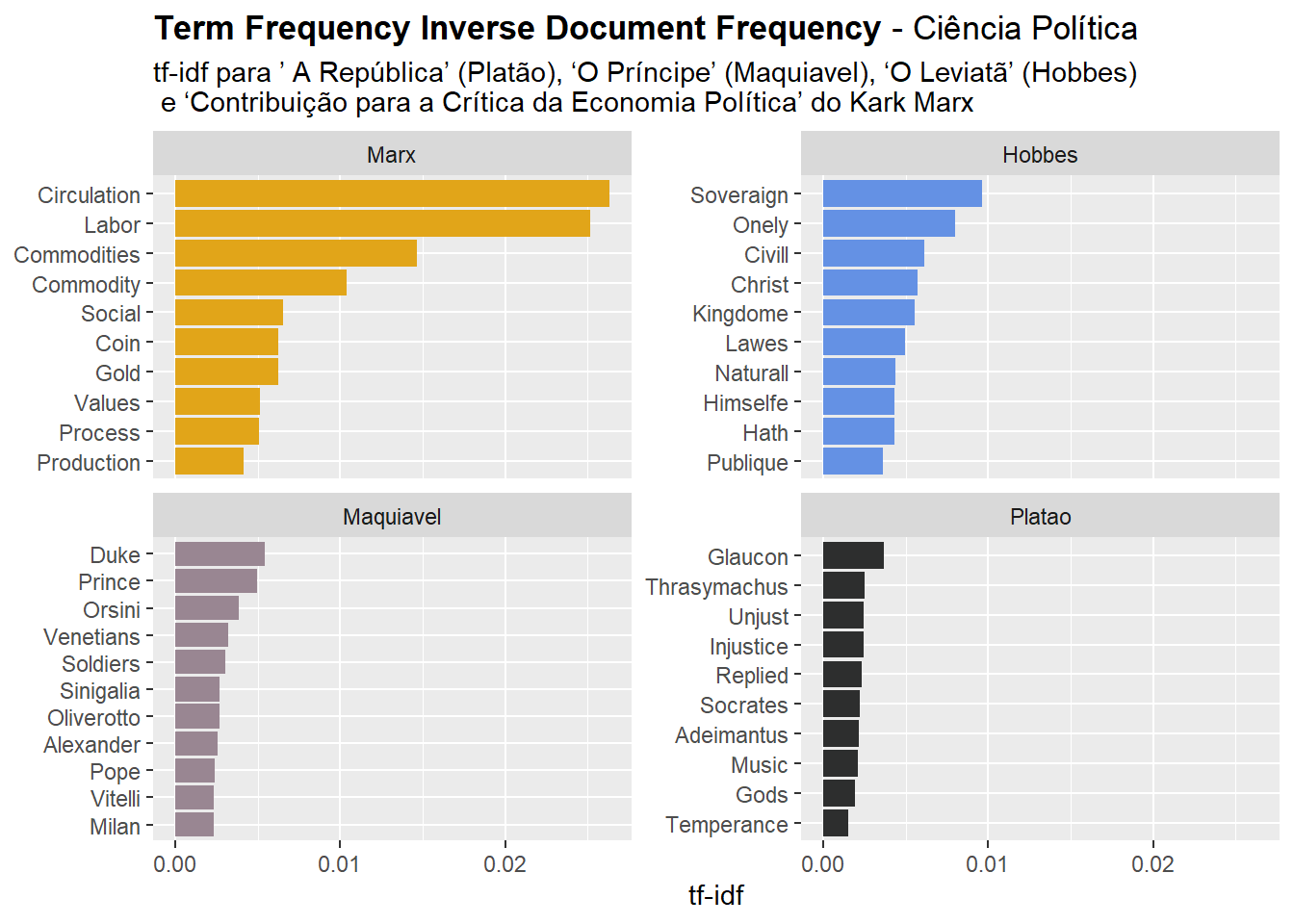
Vamos revisar cada livro e ver o que podemos aprender com nossa análise tf-idf. Minha memória desses livros está meio enferrujada, mas tentarei o meu melhor:
Hobbes: Hobbes em seu livro descreve o estado de natureza dos seres humanos e como eles podem abandoná-lo, revogando muitos de seus direitos e liberdades ao soberano que facilitaria a ordem. Em seu livro, ele descreve o soberano (soveragin) como necessário para ser rigoroso.
Maquiavel: Maquiavel fornece ao líder um guia sobre como governar seu país. Ele antecede seu livro com uma carta de apresentação ao duque, o destinatário de seu trabalho. Maquiavel ao longo do livro transmite sua mensagem com exemplos de muitos príncipes. Vários de seus exemplos são da Itália (onde ele reside), especificamente Veneza e Milão.
Platão: o livro de Platão consiste em 10 capítulos e é de longe o mais longo comparado aos outros. O livro foi escrito na forma de um diálogo com respostas entre Sócrates e seus debatedores. Ao longo da jornada de Sócrates, para descobrir qual é o significado da justiça, ele fala com muitas pessoas, entre elas Glaucon, Thrasymachus e Adeimantus. Em uma seção, Sócrates descreve uma sociedade justa com classes distintas, como os guardiões.
Marx: Na Contribuição à crítica da Economia Política Marx estuda o trabalho, a mercadoria e o dinheiro, desenvolvendo de modo sistemático e completo sua teoria do valor. Palavras como labor, value e social fazem todo sentido.
Com a análise acima, fomos capazes de explorar a exclusividade de palavras para cada livro em todos os livros. Algumas palavras nos proporcionaram grandes insights, enquanto outras não nos ajudaram necessariamente, apesar de sua unicidade, por exemplo, os nomes dos debatedores com Sócrates. Tf-idf os avalia como importantes (como defini importância aqui) para distinguir entre o livro de Platão e os outros, mas tenho certeza de que não são as primeiras palavras que vêm à mente quando alguém fala sobre a República.
A análise também mostra que a agregação de valor desta metodologia não se aplica apenas ao tf-idf - ou a qualquer outra análise estatística -, mas seu poder reside em suas habilidades explicativas. Em outras palavras, tf-idf nos fornece um valor que indica a importância de uma palavra para um determinado documento dentro de um corpus. É nosso trabalho dar esse passo extra para interpretar e contextualizar a saída.
Comparando com a contagem de palavras
Uma análise de texto comum é uma contagem de palavra. Este é um método fácil de entender que pode ser feito facilmente ao explorar texto. No entanto, contar apenas com o método de um conjunto de palavras para extrair insights pode limitar sua utilidade se outros métodos analíticos também não estiverem incluídos.
A contagem de palavras depende apenas da frequência de uma palavra, portanto, se uma palavra for comum em todos os documentos, ela poderá aparecer em todos eles e não contribuir para encontrar palavras exclusivas para cada documento.
Agora que temos nossos livros, também podemos explorar a ocorrência bruta de cada palavra para compará-la à nossa análise tf-idf acima:
## Joining, by = "word"ggplot(data = bow_books, aes(x = reorder(word_with_color,n), y = n, fill = author))+
geom_col(show.legend = FALSE)+
labs(x = NULL, y = "Word Frequency")+
coord_flip()+
scale_x_reordered()+
facet_wrap(~ author, scales = "free", ncol = 2)+
labs(title = "<b>Term Frequency</b> - Ciência Política")+
scale_fill_manual(values = plot_colors)+
theme(axis.text.y = element_markdown(),
plot.title = element_markdown(),
strip.text = element_text(color = "grey50"))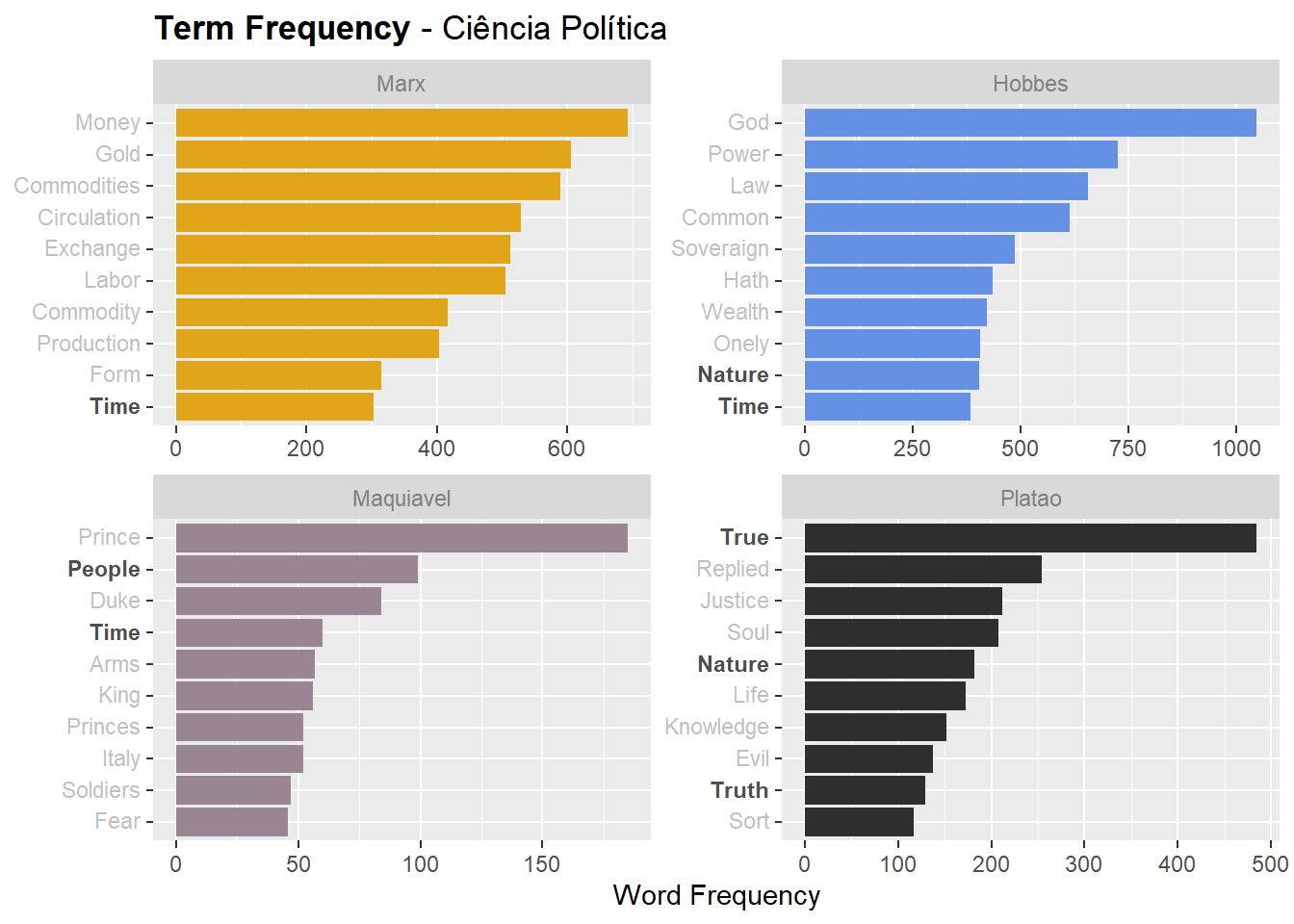
Figure 2: Gráfico do Term frequency com palavras comuns em documentos em negrito
O gráfico acima amplia, na minha opinião, a contribuição do tf-idf na busca de palavras únicas para cada documento.
Embora muitas das palavras sejam semelhantes às que encontramos na análise tf-idf anterior, também desenhamos palavras comuns em todos os documentos.
No entanto, a contagem de palavras também forneceu novas palavras que não vimos anteriormente. Aqui podemos aprender novas palavras como Power in Hobbes, Opinions in Mill e muito mais. Com o conjunto de palavras, obtemos palavras que são comuns sem controlar outros textos, enquanto o tf-idf procura por palavras que são comuns no interior, mas que são raras.
Considerações finais
Neste post, aprendemos o termo análise de frequência inversa de documentos (tf-idf) e o implementamos em quatro grandes teóricos políticos. Concluímos explorando o tfidf em comparação com uma análise de um conjunto de palavras e mostramos os benefícios de cada um. Isso também enfatiza como definimos importante: Importante para um documento por si só ou importante para um documento em comparação com outros documentos. A definição de “importante” aqui também destaca a abordagem de quantificação heurística tf-idf (especificamente o idf) e, portanto, deve ser usada com cautela. Se você conhece o desenvolvimento teórico, ficarei feliz em ler mais sobre ele.
A essa altura, você deve estar preparado para experimentar o tf-idf em um corpus de documentos que achar apropriado.